Last night Italy suffered a massive blackout, so this morning I came back from the lake Maggiore to find my server dead. The server, which runs all our mail and web sites, was (yes, was) a very old Compaq Deskpro with a Celeron 300 and twin 4Gb disks configured as a software RAID-1 array. I liked it because it was a very silent and low- consumption machine with no CPU fan, and I don't need more power than that to manage a few mailboxes, a couple of web sites, and my home LAN.
I knew it was in bad shape, but I always managed to reboot it in the past, the very few times I needed to- Today I tried everything, but the bios screen refuses to come up, and no beeps escape from the speaker at boot time.
So I wasted all day trying to let my desktop's twin machine (an Athlon 750 PC I built three years ago) see my server's two disks, and remount the RAID array. The new machine's BIOS screws up the disks geometry, and if I attach both of them on the two IDE channels, I see only the first one. Weird.
So I burned a mini-CD with tomsrtbt, transferred everything on a 20Gb disk, rebuilt the array, hotraidadded one of the two 4Gb disks, reconfigured LILO, rebooted, and LILO started spitting out error messages. Reconfigured, double checked everything, LILO comes up with a checksum error. Hmmm I'm getting old for this, I remember when it was fun but it's not anymore.
In the end I installed Grub, took the 4Gb disk off the array, fscked to death the 20Gb disk who got corrupted in the meantime, and the server is back up. Tomorrow I will buy a second 20Gb or 40Gb disk and add it to the RAID array.
The only good thing to come out of this is that I learned something more about Grub, and I really like it. If things get tough, Grub is your friend. A few useful links if you want to switch from LILO to Grub, boot a software RAID partition from Grub, convert a running system to software RAID (mainly geared towards Debian users, Slackware users may find this more useful).
My fiber optic link where this site is usually served from is still down, something to do with the Catalyst in the basement who serves the whole building, I have called a few times but all I'm getting is it will be fixed RSN. If I knew how to lockpick the rack, and I had not spent the whole day fighting disks and LILO, I would be tempted to connect my laptop and try to bring it up myself (but maybe it's not so easy anymore to reboot a Cisco and get enable permissions). Luckily I have still my ADSL link, who promptly resumed service as soon as power came back. I have switched the DNS to the ADSL address, so this site will slowly resurface on the Web, but it will be pretty slow until the fiber optic link is working again.
I admit it, I'm an architect. Not only as in IT Architect or whatever my job title of the moment is, but as in builder of houses. I graduated in 1995, and though I was totally in love with architecture, for a series of coincidences and some luck I soon found myself working in IT, which had been till then little more than a hobby.
I never got back to architecture, and soon I more or less stopped studying and researching it, but in the deep recesses of my mind things continued to work, though at a different pace. So lately I'm thinking about a research project on a period of architecture I've always found very intriguing, and usually overlooked by historians of architecture. The project will involve heavy researching in the field, which happens to be the city where I live. So it will hopefully soon be time to pick up a camera and start wandering the streets in my free time.
Photography has been the third of my passions (read: obsessions) in the past with IT and architecture, so while I wait for my ever procrastinating self to start working on this new project, I'm digging out my old pictures to scan them and put them online as a sort of mental training.
Since they will use up bandwidth, and very few people will be interested in them, my pictures category will stay confined to a row in the right menu, without making it to my blog pages. If you're interested, point your browser from time to time to my pictures area.
Sometimes being reminded of one's ignorance is not only instructive, but funny too. In a recent message on the armedbear-j-devel mailing list in reply to a non-bug I recently submitted, Peter Graves (the J developer) used an acronym I never saw before, DWIM (Paste would retain its current DWIMish behavior...).
After replying to the message, I made a quick search on DWIMI expecting to find a reference to some arcane editor of days past, but what I found was something completely different, rooted in the world of LISP gurus
/dwim/ [acronym, "Do What I Mean" (not what I say)]
- Able to guess, sometimes even correctly, the result intended when bogus input was provided.
- The BBNLISP/INTERLISP function that attempted to accomplish this feat by correcting many of the more common errors. See hairy.
- Occasionally, an interjection hurled at a balky computer, especially when one senses one might be tripping over legalisms (see legalese).
Foldoc goes on to relate a notorious incident involving DWIM, which is worth reading
Warren Teitelman originally wrote DWIM to fix his typos and spelling errors, so it was somewhat idiosyncratic to his style, and would often make hash of anyone else's typos if they were stylistically different. Some victims of DWIM thus claimed that the acronym stood for "Damn Warren's Infernal Machine!'.
In one notorious incident, Warren added a DWIM feature to the command interpreter used at Xerox PARC. One day another hacker there typed "delete *$" to free up some disk space. (The editor there named backup files by appending "$" to the original file name, so he was trying to delete any backup files left over from old editing sessions.) It happened that there weren't any editor backup files, so DWIM helpfully reported "*$ not found, assuming you meant 'delete *'". It then started to delete all the files on the disk! The hacker managed to stop it with a Vulcan nerve pinch after only a half dozen or so files were lost.
The disgruntled victim later said he had been sorely tempted to go to Warren's office, tie Warren down in his chair in front of his workstation, and then type "delete *$" twice.
Sometimes it pays to be ignorant.....
A few days ago I finally got fed up with spam, so I decided to install a spam filter on my server. After reading around a bit, I settled on Spambayes, which (apart from being written in Python) looks a very solid and well maintained project.
I don't use Outlook (I run Linux both on my server and on my desktops), so using Spambayes Outlook plugin was not an option. Since I'm using Maildir as the storage format for both SMTP and IMAP, I initially tried the Spambayes IMAP filter. Unfortunately, the filter is still in its early stage of development, and the IMAP protocol varies significantly among different server implementations. The main problems I had with the IMAP filter were its marking all new messages as read after processing (this is apparently due to my IMAP server lack of support for an obscure IMAP command), and its frequent crashes.
So after a few hours of monitoring the IMAP filter's activity, I decided to change my approach. Reading around a bit, I discovered that the venerable procmail (which I used a lot until five or six years ago) now natively supports Maildirs.
A .qmail forward file, a .procmailrc recipe and a cron job later, I had a flawless Spambayes setup. In the past 3 days, Spambayes has worked admirably with minimal training, intercepting 99% of all spam and generating zero false positives. Definitely recommended.
My .qmail file simply passes everything along to procmail for delivery:
| preline /usr/bin/procmail
My .procmailrc recipe looks like this:
PATH=$HOME/bin:/usr/bin:/bin:/usr/local/bin:. MAILDIR=$HOME/Maildir DEFAULT=$MAILDIR/ LOGFILE=$HOME/procmail.log LOCKFILE=$HOME/.lockmail :0 fw | /usr/bin/sb_filter.py :0 * ^X-SpamBayes-Classification: spam .INBOX.spambayes.spam/ :0 * ^X-SpamBayes-Classification: unsure .INBOX.spambayes.unsure/
Notice how the trailing slash in the DEFAULT delivery identifies a Maildir storage. The rest is pretty self-explanatory, apart maybe from the folder namespace, which is the one used by default by my IMAP server:
- the first directive instructs procmail to feed the message to sb_filter.py
- sb_filter processes the message and adds the X-SpamBayes-Classification header with two values, the first one marking the message as either spam/ham/unsure, the second one displaying the exact numeric spam rating (from 0 to 1)
- the second and third directives match the header on its first value for spam and unsure, and deliver the message to the appropriate Maildir
- if a message is not matched by the second or third directive, it "falls off" the chain and gets delivered to DEFAULT, which in this case is my inbox
To train the filter, I run a cron job every half hour that looks into two Maildir folders for spam and ham messages (the following lines are ofc a single crontab line):
0,30 * * * * /usr/bin/sb_mboxtrain.py -d /home/ludo/.spambayes_hammie.db -g /home/ludo/Maildir/.INBOX.spambayes.train_ham/ -s /home/ludo/Maildir/.INBOX.spambayes.train_spam/ -n >/dev/null 2>&1
Meaning, every half hour cron runs sb_mboxtrain, instructing it to use the .spambayes_hammie.db (previously created with sb_filter.py -n), and to fetch ham messages from the .INBOX.spambayes.train_ham Maildir, and spam messages from the .INBOX.spambayes.train_spam Maildir.
The Maildir directories where spam/unsure messages get delivered, and where you deposit messages to train SpamBayes, can be created either from your mail client or with the command-line utility maildirmake, provided with qmail and courier.
The last piece of information you need before running this setup, is a .spambayesrc file in your home directory. Mine contains the following lines:
[Storage] persistent_use_database = True persistent_storage_file = ~/.spambayes_hammie.db
That's all, efficient and reliable spam protection in 5 minutes or so.
I have always been an avid listener of Internet radios since my favourite music is very specialized (early or "soul" reggae, dub, and some jazz+r&b), and very unlikely to be broadcasted over the air, especially in Italy where I live.
Last night I had a further example of the power of Internet radios. Perugia, which is one of the Italian soccer teams I try to follow, was playing an away match vs Dundee FC. I was at my home office, which has no tv, so I looked up the Dundee FC site on Google, followed the link and connected to their local radio station live broadcast of the match (which I only half-managed to follow due to my unfamiliarty with the Scottish accent).
What struck me is that the above procedure involved almost no conscious thinking on my part. My interest about the match match was followed a few seconds later by a live commentary streaming out of my speakers.
So, coincidences being the stuff life is mostly made of, this morning I was not surprised to find in my aggregator a new entry on Tim Bray's blog on Radio, pointing to Doc Searls' The Continuing Death of Radio as Usual.
Doc Searls makes a few interesting points, lamenting the low quality of radio receivers (AM in cars, FM at home), the slow death of over-the-air broadcasting, and IP broadcasting as the future of the Radio.
Not that it matters to anyone, but I agree with everything he writes, except his statement that There's almost no way to get a good AM radio anymore, even if you want one.
If you don't need to integrate a radio receiver with fancy stuff like a home theatre, or distribute its audio signal throughout a house, there are plenty of excellent radios out there. They are also pretty cheap, have better audio quality than most expensive stereo equipment available on the market, are superbly good looking, and will keep their value well. The picture above should give you a clear idea of what I'm saying.
It shows a Grundig 60s console stereo set, including AM and FM radio, an equalizer, a superb antenna, four speakers, and a turntable. All integrated into a handmade wood piece of furniture. We bought a similar one from the late 50s a few months ago for less than 300 euro, and its tuning and sound qualities are excellent. Of course, sound quality is no surprise since radios from this period use tube amplifiers.
Alan Kennedy has just announced a list of Python-based HTTP proxies, a few of them may come handy when developing web applications.
And if you're wondering what I'm doing sitting in front of my computer at this hour, well this is one of those nights where I just can't get asleep.

The book Creating Applications With Mozilla is freely available at mozdev, but unfortunately it only comes as a set of HTML pages (or at least that's what I was able to find).
Having some time to waste, I set out to combine all the HTML pages in one single file, trying to improve my understanding of the wonderful elementree and elementtidy packages along the way.
The resulting script parses the files in the (hopefully) correct order, combines their HTML body elements into a single file, and fixes the internal references to point to the correct places in the new file.
The script takes about 19 seconds to run on my crappy celeron 600 machine, and the resulting file is 1.4Mb. Given that the book seems to written in Docbook, and produced with the chunked HTML Docbook XSL stylesheet, this script may serve as a starting point to reverse-engineer Docbook-produced HTML, if you ever need to do it.
A few useful links on skt-utf, an Omega TeX package that allows you to input and process Sanskrit inside LaTeX.
The skt-utf package resides at the site of the Martin-Luther-Universität Halle- Wittenberg Philosophische Fakultät Fachbereich Kunst-, Orient- und Altertumswissenschaften Institut für Indologie und Südasienwissenschaften, on a set of pages maintained by J Hanneder.
A more straightforward set of instructions for installing and using the utf-skt package can be found on the page Sanskrit Unicode Text Processing by Christian Coseru of the Australian National University. This page also covers the installation and usage of the corresponding Emacs packages.
My installation was pretty simple (I run Slackware 9.0 with Dropline Gnome)
get root privileges, then extract the package
ludo:~# tar zxvf utf-skt.tgz
find the location of your texmf-local tree
ludo:~# kpsewhich -expand-var \$TEXMFLOCAL /usr/share/texmf-local
if the directory does not exist yet, create it
ludo:~# mkdir /usr/share/texmf-local
copy the contents of the extracted archive's texmf directory under your texmf-local tree
ludo:~# cp -R utf-skt/texmf/* /usr/share/texmf-local/
update the TeX files index
ludo:~# /usr/share/texmf/bin/texhash
The installation is now complete, let's revert back to a normal system user to test the package, using the example documents contained in the utf-skt/user/examples directory extracted from the archive.
Before starting, it will be useful to note that utf-skt is an Omega package (Omega is a TeX extension "designed for the typesetting of all the world's languages"), and so the commands used to generate .dvi files from the .tex sources are different from standard LaTeX. Instead of latex we will need to use lambda, instead of dvips odvips.
Let's create a PDF file from the Transliterated.tex example file (I only list the commands, without their output):
ludo:~/download/skt/utf-skt/user/examples$ lambda Transliterated.tex ludo:~/download/skt/utf-skt/user/examples$ lambda Transliterated.tex ludo:~/download/skt/utf-skt/user/examples$ odvips Transliterated.dvi ludo:~/download/skt/utf-skt/user/examples$ ps2pdf Transliterated.ps
Supposing you got no errors (due to problems with your TeX or utf-skt installations), you should now have a Transliterated.pdf file. If you open the file in Acrobat Reader though, you will notice that the fonts are all blurred. The PDF will print ok, but reading it on-screen is a pain. This is due to dvips including bitmap versions of the fonts used in the document, instead of their outlines.
After a bit of digging around in Google, and experimenting with different solutions to this problem, I found a thread in the debian-users list that worked (keep in mind I'm a novice TeX user, so other solutions may be better for different setups, etc.):
In your home directory, make (or modify it if it already exists) a file
named .dvipsrc which must contain the lines:
p+ psfonts.cmz
p+ psfonts.amz
Make sure that the LaTeX preamble of your LyX file (or the part before
\begin{document} if you are using straight LaTeX files) contains:
\usepackage[T1]{fontenc}
\usepackage{ae,aecompl}
Re-running odvips and ps2pdf the resulting PDF looks as in the image above. The document source in the image is opened in Gnome 2.4's gedit.
Yesterday I set up to write unit tests for a few PHP classes I'm refactoring. Given my usual tendency to set aside serious tasks and concentrate on eye candy, after a few tests I decided to write my own test runner (something I've done at least twice before, never storing away the code for later use).
My test runner builds on a few assumptions:
- the tests live in a web accessible directory
- every php file in the directory with a name starting with test is a test case
- every test file contains one case class extending PHPUnit_TestCase
- every test class has the same name as the file where it resides
- test cases are all the methods of the class whose names start with test
- you run tests and see results with a web browser
The main test runner features are:
- conditional execution of one or more test cases based on an HTML form
- run only/exclude a test with a single click of the mouse
- display aggregate test results by suite, showing counts for successes/failures and a warning indicator if any have been raised
- optionally expand test results to show results/failures for single test cases
- remember each suite visibility status (collapsed/expanded) for subsequent runs
- collect PHP warnings emitted during each test case run and display them under the appropriate test suite
I made a few screenshots, showing a collapsed view of all available suites, the same for a single suite, with a warning indicator, and one suite expanded, showing test cases results and warnings.
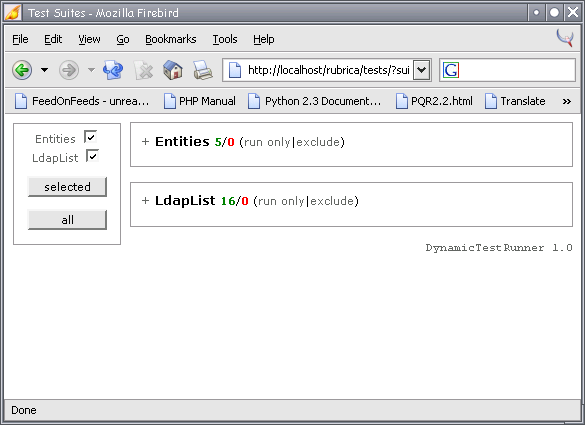{kind=link}
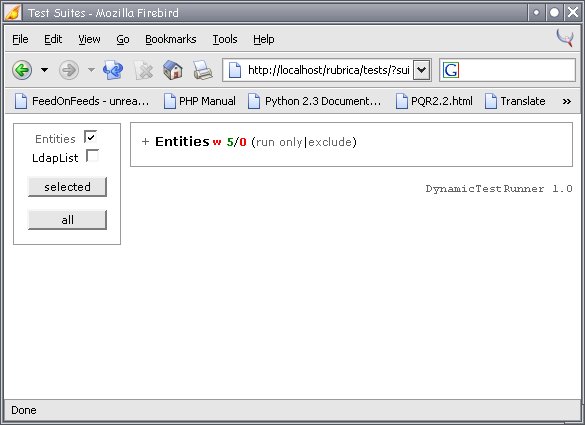{kind=link}
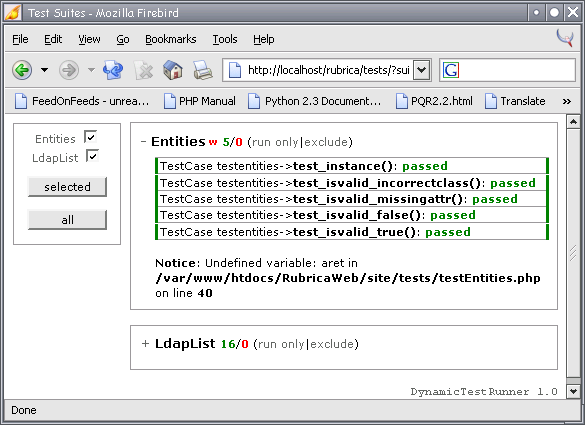{kind=link}
The DynamicTestRunner code only needs to include the PEAR version of PHPUnit. Using a templating engine would have made the code more understandable, but at the cost of introducing a dependency.
If you want to preserve the option of being able to run each test file on its own, you can test if it has been called by testRunner with a simple if statement at the end of each test file (substituing of course testEntities with the name of the class declared in the file):
if (!isset($_SERVER['SCRIPT_FILENAME']) ||
$_SERVER['SCRIPT_FILENAME'] == __FILE__) {
$suite = new PHPUnit_TestSuite('testEntities');
$result = PHPUnit::run($suite);
echo $result->toString();
}
Tonight, while trying to scan very old (100 yrs or so) negatives on my cheap ScanJet 3400c, I managed to read the very good article The Mad Hatter meets the MCSE, mentioned on a Slashdot post.
As I wrote in a past entry, I saw Sun Rays and MadHatter at Sun's Milan offices a few weeks ago, and I was deeply impressed. This article examines in detail the impact of introducing a Lintel architecture in the Enterprise.
What I liked most from tonight's quick read of this article (gonna read and summarize it for the big shots tomorrow at the office) are a few well-made points:
- a Linux integration in the enteprise is a potential and very expensive failure, if it has to adapt to a Windows-based infrastructure
- a Unix-based architecture is unlikely to evolve in Windows or Mainframe centric environments due to cultural differences between the two worlds
- Sun's Unix Business Architecture (UBA) has a tremendous potential and could change the way enterprises design and manage their IT infrastructures
Definitely a recommended reading.
Hmmm...maybe people do stupid searches on them. I was looking at the google searches people come on my site from, and noticed a good one: x x x stuff (without the spaces of course). I promptly opened it, and...wow I'm in 7th position, all thanks to a masked email address in my post on the J editor. Due to insistent requests from my gf, I changed the email address to to show z characters instead of x.
One of the things I like best of Python is the interactive console. I often use it to do quick manipulations on text files, and every time I wonder how I did manage before learning Python, when I wrote Perl or PHP scripts for similar things (yes I know that Perl has useful command line options for stuff like that, but with the Python console you can poke around and see the data you're manipulating interactively, get help on commands, etc.).
So today I set to the task of removing unneeded CSS classes from a huge HTML file I did not produce myself.
Getting the data from a file is a one-liner:
/-(ludo@pippozzo)-(27/pts)-(15:44:06:Sat Sep 06)--
\-($:~)-- python
Python 2.3 (#1, Aug 5 2003, 15:11:52)
[GCC 3.2.3] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> all = file('xxxxxxxxxx.html', 'r').read()
Then we import the re module and obtain a list of all css classes used in the file, removing duplicates:
>>> import re
>>> r = re.compile('class="([^"]+)"')
>>> styles = [s for s in r.findall(all) if s not in locals()['_[1]'].__self__]
The duplicate removal comprehension looks like a clever Perlish hack, but I'm in the console and it's nice to be able to do everything in one line. I copied it from the Python Cookbook entry The Secret Name of List Comprehensions by Chris Perkins, who warns that It should come as no surprise to anyone that this is a totally undocumented, seat-of- your-pants exploitation of an implementation detail of the Python interpreter. There is absolutely no guarantee that this will continue to work in any future Python release.
Now that we have the list of classes in use, we can remove unneeded ones and save the processed content on the original file:
>>> r = re.compile(r"""(?ms)^(\S*\.(\S+)\s+\{[^\}]+\}\n)""")
>>>
>>> for style in r.findall(all):
... if not style[1] in styles:
... all = all.replace(style[0], '')
...
>>> file('xxxxxxxxxx.html', 'w').write(all)
Storing the styles in a dictionary is more efficient (not that it matters in this quick console run), and eliminates the need of using the duplicate removal hack. Here is a version using a dictionary:
>>> import re
>>> all = file('xxxxxxxxxx.html', 'r').read()
>>> r = re.compile('class="([^"]+)"')
>>> styles = {}
>>> for s in r.findall(all):
... styles[s] = None
...
>>> r = re.compile(r"""(?ms)^(\S*\.(\S+)\s+\{[^\}]+\}\n)""")
>>> for style in r.findall(all):
... if not style[1] in styles:
... all = all.replace(style[0], '')
...
>>> file('xxxxxxxxxx.html', 'w').write(all)
update: the lines above worked for the particular file I was editing, a general solution would probably need a few changes:
- In the second regexp, used to identify style class declarations, I assume the class identifier is anchored at the beginning of a line, which is not always the case
- I look for style class declarations in the whole file, which is pretty pointless (but saves typing a few lines of code in the console and works for the specific HTML file in question); style class declarations are obviously inside a <style></style> block, so it's better to limit the scope of the second findall() to the contents of the style block(s), speeding up the search/replace and reducing the chance of errors in the regexp match (for example, matching blocks of C/Java/PHP source in the body of the document)
- maybe use a scanner object instead of the second findall, and replace using the match position, as Fredrik Lundh explains in Using Regular Expressions for Lexical Analysis
My current technical reading is the excellent book Text Processing in Python by David Mertz. In chapter 1 David expresses with his usual clarity a couple of concepts I usually unconsciously follow in my Python programming, but which are important enough to be repeat here as a reminder to myself.
[...] an important principle of Python programming makes types less important than programmers coming from other languages tend to expect. According to Python's "principle of pervasive polymorphism" (my own coinage), it is more important what an object does than what it is.
David then proceeds to describe a few practical cases where pervasive polymorphism is useful, like working on file-like objects.
One common way to test a capability in Python is to try to do something, and catch any exceptions that occur (then try something else).
One of the main reasons why I like Python so much compared to other languages is the incredible usefulness of its exception mechanism. After all, many of the things we experiment or learn in life we do by trial and error, and using this same method in programming just fits your brain.
Since it was announced on the PEAR newsgroup a few years ago, I have been using the Var_Dump class by Frederic Poeydomenge as one of my favourite PHP development tools. Dumping variables at strategic places has always been a practical and effective (if a bit simple) method of debugging in PHP and other languages. Unfortunately, when you're working with complex data or with class instances, using the echo construct or the var_dump function is not very useful, unless you go to great lengths to extract what you really need to display from your data.
Var_Dump is a class that assists you in exactly this task, extracting all available information from your data and displaying it in a variety of ways. It is the PHP analogous to the Python pprint module, and one could spend an interesting few minutes comparing the two very different PHP and Python solutions to dumping (or pretty printing, which is more what's happening here) data.
In its simplest form, the Var_Dump class can be used through a single static method, and a few optional constants. At the other end of the scale, a Var_Dump instance can be customized through skins, color sets, and display options to tailor its output to your exact needs. In this brief document, we will show examples of its use through a static method, since it's the one you most probably will resort to during development. More complex examples can be found on the author's site.
We start by importing the class code, and setting up a few variables and a class instance, that we will feed to Var_Dump.
require_once 'Var_Dump.php';
$a = array(0,1,2,34);
$b = array('a'=>'something', 'b'=>0, 0=>'b', 'c'=>$a);
class B {}
class A extends B {
var $a;
var $b = 1;
function a($a) {
$this->a = $a;
}
}
$a_inst = new A(2);
Once we have that out of the way, we start feeding our data to Var_Dump by calling its display method as a static class method. First the simple array, without passing any extra argument to display.
Var_Dump::display($a);
Our friendly class spits out the following output:
0 Long (0) 1 Long (1) 2 Long (2) 3 Long (34)
Nice, isn't it? Ok, let's start using the optional arguments to display, and feed it something a bit more complex.
Var_Dump::display($b, 'b');
The second argument we passed to display in this example is the name of a key not to display, mainly used to avoid printing deeply nested data structures. As we can see from the following output, Var_Dump does a remarkable job of printing multidimensional arrays.
a String[9] (something)
b Not parsed ()
0 String[1] (b)
c Array(4)
+ 0 Long (0)
| 1 Long (1)
| 2 Long (2)
+ 3 Long (34)
On to the class instance, and the third argument you can pass to display.
Var_Dump::display($a_inst, null, VAR_DUMP_DISPLAY_MODE_HTML_TABLE);
As you have probably guessed, the third argument controls the output generated by Var_Dump through a few self-explanatory constants:
- VAR_DUMP_DISPLAY_MODE_TEXT
- VAR_DUMP_DISPLAY_MODE_HTML_TEXT
- VAR_DUMP_DISPLAY_MODE_HTML_TABLE
The output of our instance is pretty interesting, as Var_Dump squeezes all available bits of information from it, including its class and its base classes, if any.
|
The fourth, and last of the arguments you can pass to display is again a constant from a self-explanatory set:
- VAR_DUMP_NO_CLASS_VARS
- VAR_DUMP_NO_CLASS_METHODS
- VAR_DUMP_NO_CLASS_INFO
Let's see what happens if we feed our instance to display, by using the VAR_DUMP_NO_CLASS_INFO constant, and reverting to the simpler output.
Var_Dump::display($a_inst, null,
VAR_DUMP_DISPLAY_MODE_HTML, VAR_DUMP_NO_CLASS_INFO);
Class name String[1] (a)
Parent class String[1] (b)
Object vars Array(2)
+ a Long (2)
+ b Long (1)
That's all for tonight, if you have suggestions for PHP topics you would like to read here, drop me a message.

A few days ago I read that Robert J. Sawyer's Hominids had won the 2003 Hugo Award as best novel, so I put aside Terry Pratchett's Moving Pictures for a while, grabbed a copy of Hominids and started reading.
I finished the book tonight, and I have to say I am a bit disappointed. The book, as many sf/fantasy books or movies (one of my favourites being the movie Groundhog Day), is built around an interesting idea involving space or time. In Hominids, Sawyers imagines that somewhere in Earth's past a duplicate universe split off from our own, where Neanderthal men evolved instead of our race.
Unfortunately, this idea is just about the only good thing I found in this book. The plot is mediocre, the characters lack depth and psychological introspection, and the artifices the author uses to bridge the language barrier between the two worlds are really simplistic. Moreover, a good part of the book deals with a court case between the Neanderthals, and I found the topic really boring (maybe it appeals to US and Canadian readers) and its development superficial.
What I (somewhat) liked in this book is its rythm, and the wealth of notions about quantum theory and anthropology. All in all, it's not one of the worst books I have read lately, and if you liked Michael Crichton's Sphere or his Jurassic books maybe you will find Hominids a good read, though a simplistic one.
update: Out of curiosity, I had a look at the Amazon reviews for Hominids, and among all the celebrative reviews there's one by JR Dunn which is worth quoting
This is Wellsian didactic SF on the kindergarten level. Intelligent Neanderthals turn out to be bisexual, atheist Canadians, and are willing to tell us about. And tell us about it. And tell us about it. Passage unto page unto chapter. (And just think--this is the beginning of a trilogy.)If that sounds like your thing, go to it. Otherwise, your time would be better spent reading... oh, the government-mandated cooking directions in chicken packages. You'll learn a lot more of value there.
Ouch! Well said, and in far less words than I used. Glad to know I'm not the only one to think that this book is overrated.
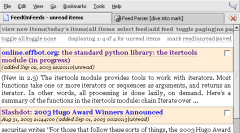
I noticed from my logs that somebody using feedonfeeds is subscribed to my blog. Feedonfeeds is a nice PHP aggregator/reader, written by Steve Minutillo.
After shopping around for a while for a news aggregator, I settled on feedonfeeds a couple of months ago for a couple of reasons:
- it has very few dependencies (any version of MySQL is ok, and a sufficiently recent PHP)
- it is a server-side aggregator, allowing me to read news from home/office/wherever
- it installs in a couple of minutes anywhere you can put a few PHP files
- it is easily customizable
- it works =)
So I installed feedonfeeds, and staying up to date has become a joy.
Never satisfied, after a couple of days of use I decided I absolutely needed a few features that feedonfeeds was lacking. So I set about refactoring it, and the project turned out to be a full rewrite. As usual with these things, the result is a half-completed app, so that I now have the (minor) features I wanted, and lack most basic ones feedonfeeds provides out of the box. =)
My rewrite is template-based, and factors out most common operations (eg SQL statements etc) in a few classes, instead of using lots of functions. So far, I have:
- a fully functional news reading page with save/read/unread flagging, paging by page and by date, etc. (the one you see in the picture above)
- a half-working feeds page, showing subscribed feeds and their new/read/saved news counts, and controls to add/edit/remove a feed that get you nowhere =)
- an improved SQL schema, using InnoDB tables support for foreign keys
- a new Python backend based on Mark Pilgrim's ultra-liberal feed parser, supporting the parser's use of HTTP features (If-None-Match and If- Modified-Since headers when requesting an RSS feed, and parsing the ETag and Last-Modified headers) to limit transfers; the uhm "backend" is an amazing 75 lines of code, including a 20 or 30 lines string containing the SQL schema =)
update: I finally managed to add the most important missing functionality to my feedonfeeds rewrite, and package it.